Logistic Regression And Regularization
Логистическая регрессия
Всем привет, меня зовут Хворостяный Вячеслав. В этой статье я продолжу тему имплементации базовых алгоритмов “машинного обучения” с помощью Python. В предыдущей статье был рассмотрен алгоритм линейной регрессии, а также такой метод оптимизации как градиентный спуск. В этой статье разберем логистическую регрессию, регуляризацию и применения алгоритмов на практике.
Существует два основных типа алгоритмов “машинного обучения” - “обучение с учителем” (“supervised learning”) и “обучение без учителя” (“unsupervised learning”). В свою очередь, “обучение с учителем” делиться на регрессионные алгоритмы и алгоритмы классификации. Логистическая регрессия принадлежит к типу “supervised learning”, и, несмотря на название, является алгоритмом классификации. “Обучение с учителем” значит, что у нас уже есть некоторое количество данных где известны как значение аргументов, так и значения самой функции, и наша задача состоит в том, чтобы “обучится” на этих, уже размеченных данных.
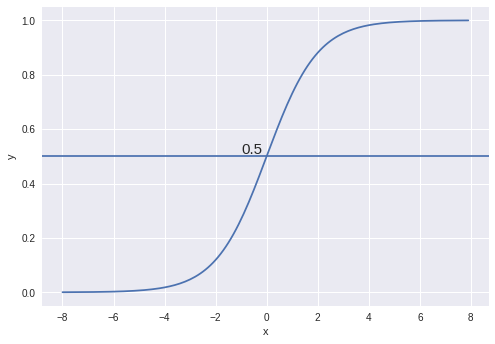
В основе алгоритма логистической регрессии лежит экспоненциальная кривая или сигмоида, которая разделяет объекты на два класса. Функция сигмоиды часто используется как функция активации в нейронных сетях, наряду с гиперболическим тангенсои и ReLU.
Где
- функция прямой (линейная регрессия)
- гипотеза
- сигмоида
Задача алгоритма - вычислить вероятность того, что элемент принадлежит к одному из классов. Значения функции находятся в границах от [0,1], самый простой способ - округлить все значения больше 0.5 до единицы, порог можно задать и выше, в том случае, если верно определить позитивный класс является задачей более критичной чем отличить красный носок от белого.
Cигмоида:
Кост-функция в случае логистической регрессии будет выглядеть так:
Датасет может иметь много полей или “фичей”, но не все фичи вносят одинаковый вклад в принятие алгоритмом решения. По сути признаки (фичи) с малым вкладом являются “шумом”, который накладывает негативный след на работу алгоритма, не позволяя модели обобщить обсчеты. Этот эффект называют “переобучение” или “overfitting”, алгоритм “заучивается” на текущих данных и плохо работает с новыми. В свою очередь недостаточное количество фичей вызывает “недообучение” или “underfitting”, модель плохо показывает себя как на тренинг сете, так и на тесте, сложно оценить стоимость автомобиля, зная только что у него сиденья с подогревом, согласитесь. Серебряной пули нет, и к каждой проблеме нужно подходить индивидуально, но при большом количестве фичей регуляризация спасает от обучения модели на “шуме”.
Регуляризация
Регуляризация - подход, который позволяет снизить сложность модели за счет “штрафования” вектора параметров .Это один из эфективных методов борьбы с “переобучением”, наряду с кросс-валидацией и уменьшением количества фичей, о которых мы поговорим позже. Регуляризация дает возможность выделить фичи,которые вносят наибольший вклад в принятия решения, и снизить влияние фич создающих “шум”. Существует два вида регуляризации - L1 и L2, выбор вида регуляризации отвечает на вопрос “как штрафовать”. Рассмотрим различия между ними.
L1 и L2 регуляризация
L1 регуляризация
L1 регуляризация или Лассо представлена в виде суммы модулей всех элементов вектора параметров , то есть L1 нормы. Этот тип регуляризации хорошо показывает себя на простых моделях, она устойчива к выбросам (outliers), “недорогая” с точки зрения вычислительных операций, хороша для прореживания фичей, сводя к нулю менее существенные. L1 регуляризация часто используется для выбора фичей (“feature selection”).
Где - гиперпараметр, определяющий насколько “штрафовать” вектор параметров, подбирается вручную, если выбрать слишком маленьким, модель все так же будет “переобучаться”, если слишком большим - “недообучаться”, мы подбираем , пока точность нас не будет устраивать.
L2 регуляризация
L2 регуляризация является суммой квадратов всех элементов вектора параметров . Применяется к сложным моделям, не устойчива к выбросам, не сводит значения вектора параметров к нулю, и не прореживает фичи, но в отличие от L1 хорошо показывает себя когда все входные фичи имеют размерность одного порядка.
Имплементация на Python
import pandas as pd, numpy as np
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
%matplotlib inline
# для примера возьмем результаты обследования молочной железы на предмет рака
df = pd.read_csv('https://raw.githubusercontent.com/vkhvorostianyi/vkhvorostianyi.github.io/master/assets/data.csv')
df['class'] = 1
df.loc[df['diagnosis'] == 'B', 'class'] = 0
X_ = df.iloc[:,2:-2]
Y = df.iloc[:,-1]
# расделим данные на трейн сет и тест сет
train_set_x, test_set_x, train_set_y, test_set_y = train_test_split(X_, Y, test_size=0.33, random_state=42)
def get_X_with_ones(X):
"""нормализируем данные и добавляем столбик единиц"""
X = np.array(X)
mean,std = X.mean(), X.std()
X = (X - mean) / std
m = len(X)
X = np.c_[np.ones(m),X].T
return X
# добавим столбик единиц
X = get_X_with_ones(train_set_x)
initial_theta = np.zeros((X.shape[0], 1))
def sigmoid(z):
return 1/ (1 + np.exp(-z))
def costFunctionReg(theta, X, y ,Lambda):
m=len(y)
y=y[:,np.newaxis] # аналог reshape()
predictions = sigmoid(X.T @ theta) # @ - оператор векторного умножения, аналог np.dot
error = (-y * np.log(predictions)) - ((1-y)*np.log(1-predictions))
cost = 1/m * sum(error)
regCost= cost + Lambda/(2*m) * sum(theta**2)
j_0 = 1/m * (X @ (predictions - y))[0]
j_1 = 1/m * (X @ (predictions - y))[1:] + (Lambda/m)* theta[1:] # место, где происходит вся магия, "штрафуем" вектор параметров
grad= np.vstack((j_0[:,np.newaxis],j_1))
return regCost[0], grad
def gradientDescent(X,y,theta,alpha,num_iters,Lambda):
m=len(y)
J_history =[]
for i in range(num_iters):
cost, grad = costFunctionReg(theta,X,y,Lambda)
theta = theta - (alpha * grad)
J_history.append(cost)
return theta , J_history
theta , J_history = gradientDescent(X,train_set_y, initial_theta,.5,200,0.5)
print("Cost func:\n", J_history[-1])
Выведем результат:
X = get_X_with_ones(test_set_x)
s = np.squeeze(sigmoid(theta.T @ X))
d = np.zeros(s.shape[0])
d[s>.5] = 1
stat = np.unique(d==test_set_y, return_counts=True) # количество совпавших и не совпавших диагнозов
print(f'Accuracy:{stat[1][1]/sum(stat[1]):.2}') # доля совпавших ~98%
Ссылки на используемые ресурсы:
https://towardsdatascience.com/regularization-in-machine-learning-connecting-the-dots-c6e030bfaddd
https://towardsdatascience.com/andrew-ngs-machine-learning-course-in-python-regularized-logistic-regression-lasso-regression-721f311130fb
https://towardsdatascience.com/l1-and-l2-regularization-methods-ce25e7fc831c
https://medium.com/datadriveninvestor/l1-l2-regularization-7f1b4fe948f2
https://towardsdatascience.com/over-fitting-and-regularization-64d16100f45c